Java NIO - Netty ByteBuf 详解
Netty ByteBuf 简介
ByteBuf 解决的问题
在 Netty 的高性能架构中,ByteBuf 是其最核心的基石。简单来说,它是 Netty 对 Java 原生 java.nio.Buffer 的重新实现和深度增强。如果把网络传输比作物流,那么 ByteBuf 就是那个装载货物的 “智能集装箱”。
为什么不直接用 Java 原生的 ByteBuffer?原因是 Java 原生的 ByteBuffer 在实际开发中存在两个痛点:
- 读写共用一个指针:切换读写模式必须频繁调用 flip() 或 rewind(),逻辑极其繁琐且易出错。
- 固定长度:一旦分配,长度无法自动扩展。
ByteBuf 的核心革新:双指针设计。Netty 的 ByteBuf 内部维护了两个独立的索引指针:readerIndex 和 writerIndex。你可以在同一个缓冲区里同时进行读和写,完全不需要 flip()。
ByteBuf 的内存模型
Netty 根据使用场景,提供了两种主要的内存实现:

对于网络 IO 频繁的后端服务,通常推荐使用 Direct ByteBuf,因为它可以直接被操作系统的网卡驱动访问,避免了内核态与用户态之间的数据拷贝。
ByteBuf 的组成部分
ByteBuf是一个字节容器,内部是一个字节数组。从逻辑上来分, 字节容器内部可以分为四个部分:
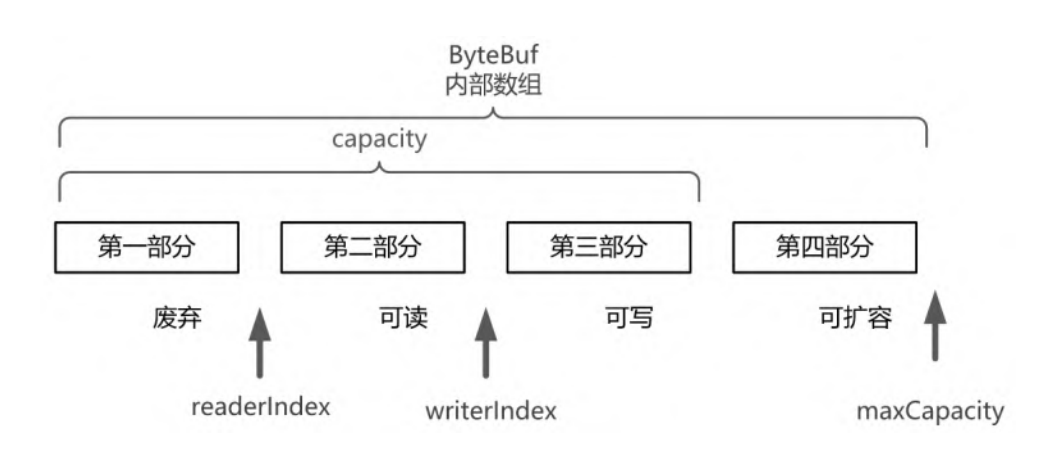
- 第一部分是已用字节,表示已经使用完的废弃的无效字节;
- 第二 部分是可读字节,这部分数据是ByteBuf保存的有效数据,从ByteBuf 中读取的数据都来自这一部分;
- 第三部分是可写字节,写入ByteBuf的 数据都会写到这一部分中;
- 第四部分是可扩容字节,表示的是该 ByteBuf最多还能扩容的大小。
核心优势-零拷贝与池化
Netty 的 ByteBuf 支持多种 “组合” 操作。例如 CompositeByteBuf 可以将多个 ByteBuf 逻辑上合并为一个,而无需在内存中进行实际的字节拷贝。这在处理 TCP 拆包/组包时性能优势巨大。
在高并发下,频繁申请和释放内存会导致严重的 GC 压力。Netty 从 4 版本开始引入了 PooledByteBufAllocator(类似于线程池的概念),极大降低了堆外内存溢出风险和 GC 频次。
- 预先申请一大块内存。
- 当 Handler 需要时,从池中借出一个 ByteBuf。
- 使用完后归还,而不是交给 GC 回收。
ByteBuf 的属性和方法
重要属性
ByteBuf 通过三个整数类型的属性有效地区分可读数据和可写数据的索引,使得读写之间相互没有冲突。这三个属性定义在 AbstractByteBuf 抽象类中,分别是:
readerIndex(读指针):指示读取的起始位置。每读取一个字 节,readerIndex 自动增加1。一旦readerIndex 与 writerIndex 相等,则表示 ByteBuf 不可读了。writerIndex(写指针):指示写入的起始位置。每写一个字 节,writerIndex自动增加1。一旦增加到writerIndex 与 capacity() 容量相等,则表示 ByteBuf 不可写了。注意, capacity() 是一个成员方法,不是一个成员属性,表示 ByteBuf 中可以写入的容量,而且它的值不一定是最大容量值。maxCapacity(最大容量):表示ByteBuf可以扩容的最大容量。当向 ByteBuf 写数据的时候,如果容量不足,可以进行扩 容。扩容的最大限度由maxCapacity来设定,超过 maxCapacity 就会报错。
重要方法
ByteBuf的方法大致可以分为三组。
第一组:容量系列
- capacity():表示ByteBuf的容量,是废弃的字节数、可读字节 数和可写字节数之和。
- maxCapacity():表示ByteBuf能够容纳的最大字节数。当向 ByteBuf中写数据的时候,如果发现容量不足,则进行扩容,直 至扩容到maxCapacity设定的上限。
第二组:写入系列
- isWritable():表示 ByteBuf 是否可写。如果 capacity() 容量大 于 writerIndex 指针的位置,则表示可写,否则为不可写。注 意:isWritable() 返回 false 并不代表不能再往 ByteBuf 中写数据了。如果 Netty 发现往ByteBuf 中写数据写不进去,就会自动扩容 ByteBuf。
- writableBytes():取得可写入的字节数,它的值等于容量 capacity() 减去 writerIndex。
- maxWritableBytes():取得最大的可写字节数,它的值等于最 大容量maxCapacity减去writerIndex。
- writeBytes(byte[] src):把入参src字节数组中的数据全部写到ByteBuf。这是最为常用的一个方法。
- writeXxx(Xxx value):写入基础数据类型的数据。这里包含了八种大基础数据类型:writeByte()、writeBoolean()、writeChar()、 writeShort()、writeInt()、writeLong()、writeFloat()、 writeDouble()。
- setXxx(Xxx value):基础数据类型的设置,不改变 writerIndex 指针值。这里包含了八大基础数据类型的设置,即 setByte()、setBoolean()、 setChar()、setShort()、setInt()、setLong()、 setFloat()、setDouble()。setXxx 系列与 writeXxx 系列的不同点是setXxx 系列不改变写指针 writerIndex 的值,writeXxx 系列会改变写指针 writerIndex 的值。
- markWriterIndex() 与 resetWriterIndex():前一个方法表示把当前的写指针 writerIndex 属性的值保存在markedWriterIndex 标记属性中;后一个方法表示把之前保存的markedWriterIndex 的值恢复到写指针writerIndex属性中。这两个方法都用到了标 记属性markedWriterIndex,相当于一个写指针的暂存属性。
第三组:读取系列
- isReadable():返回ByteBuf是否可读。如果writerIndex指针的值大于readerIndex指针的值,则表示可读,否则为不可读。
- readableBytes():返回表示ByteBuf当前可读取的字节数,它 的值等于writerIndex减去readerIndex。
- readBytes(byte[] dst):将数据从ByteBuf读取到dst目标字节 数组中,这里dst字节数组的大小通常等于readableBytes()可 读字节数。这个方法也是最为常用的方法之一。
- readXxx():读取基础数据类型。可以读取八大基础数据类 型:readByte()、readBoolean()、readChar()、 readShort()、readInt()、readLong()、readFloat()、 readDouble()。
- getXxx():读取基础数据类型,并且不改变readerIndex读指 针的值,具体为 getByte()、getBoolean()、getChar()、 getShort()、getInt()、getLong()、getFloat()、 getDouble()。getXxx 系列与 readXxx 系列的不同点是 getXxx 系列不会改变读指针 readerIndex 的值,readXxx 系列会改变读指针 readerIndex 的值。
- markReaderIndex() 与 resetReaderIndex():前一种方法表示把 当前的读指针readerIndex保存在markedReaderIndex属性中; 后一种方法表示把保存在markedReaderIndex属性的值恢复到读 指针readerIndex中。markedReaderIndex属性定义在 AbstractByteBuf 抽象基类中,是一个标记属性,相当于一个读 指针的暂存属性。
一个基础测试:
1 | public class DemoTest { |
1 | ---------------- 动作:分配 ByteBuf(9, 100) ---------------- |
ByteBuf 的引用计数
JVM中使用“计数器”(一种GC算法)来标记对象是否“不可达” 进而收回,Netty也使用了这种手段来对ByteBuf的引用进行计数。Netty之所以采用“计数器”来追踪ByteBuf的生命周期,一是能 对Pooled ByteBuf进行支持,二是能够尽快“发现”那些可以回收的 ByteBuf(非Pooled),以便提升ByteBuf的分配和销毁的效率。ByteBuf 实现了 ReferenceCounted 接口。
- 每当被引用,调用
byteBuf.retain()方法时,计数 +1。 - 调用
byteBuf.release()时,计数 -1。 - 当计数为 0 时,内存会被立即回收(如果是池化对象则回到池中)。
这就是为什么你在之前的代码里看到 finally { ReferenceCountUtil.release(msg); }。在 Netty 中,谁最后消费了 ByteBuf,谁就有责任释放它。
运行后我们会发现:最后一次retain()方法抛出了 IllegalReferenceCountException异常。原因是:在此之前,缓冲区 buffer的引用计数已经为0,不能再retain了。也就是说:在Netty 中,引用计数为0的缓冲区不能再继续使用。
1 |
|
为了确保引用计数不会混乱,在Netty的业务处理器开发过程中应该坚持一个原则:retain()和release()方法应该结对使用。对缓冲区 调用了一次retain(),就应该调用一次release()。大致的参考代码如下:
1 | public void handlMethodA(ByteBuf byteBuf) { |
如果retain()和release()这两个方法一次都不调用呢?Netty在 缓冲区使用完成后会调用一次release(),就是释放一次。例如,在 Netty流水线上,中间所有的业务处理器处理完ByteBuf之后会直接传 递给下一个,由最后一个Handler负责调用其release()方法来释放缓冲区的内存空间。当ByteBuf的引用计数已经为0时,Netty会进行ByteBuf的回收, 分为以下两种场景:
- 如果属于池化的ByteBuf内存,回收方法是:放入可以重新分配的ByteBuf池,等待下一次分配。
- 如果属于未池化的ByteBuf缓冲区,需要细分为两种情况: 如果是堆(Heap)结构缓冲,会被JVM的垃圾回收机制回收;如果是直接(Direct)内存类型,则会调用本地方法释放外部内存 (unsafe.freeMemory)。
除了通过ByteBuf成员方法retain()和release()管理引用计数之 外,Netty还提供了一组用于增加和减少引用计数的通用静态方法:
- ReferenceCountUtil.retain(Object):增加一次缓冲区引 用计数的静态方法,从而防止该缓冲区被释放。
- ReferenceCountUtil.release(Object):减少一次缓冲区引 用计数的静态方法,如果引用计数为0,缓冲区将被释放。
ByteBuf 的分配器
分配器简介
Netty 通过 ByteBufAllocator 分配器来创建缓冲区和分配内存空 间。Netty 提供了两种分配器实现: PoolByteBufAllocator 和 UnpooledByteBufAllocator。
PoolByteBufAllocator(池化的ByteBuf分配器)将 ByteBuf 实例放入池中,提高了性能,将内存碎片减少到最小;池化分配器采用了 jemalloc 高效内存分配的策略,该策略被好几种现代操作系统所采 用。 UnpooledByteBufAllocator 是普通的未池化ByteBuf分配器,没有把 ByteBuf 放入池中,每次被调用时,返回一个新的ByteBuf实例;使用完之后,通过Java的垃圾回收机制回收或者直接释放(对于直接内存而言)。
为了验证两者的性能,大家可以做一下对比试验:
(1)使用UnpooledByteBufAllocator方式分配ByteBuf缓冲区, 开启10000个长连接,每秒所有的连接发一条消息,再看看服务器的内存使用量情况。
实验的参考结果:在较短时间内,就可以看到程序占到10GB多的 内存空间,随着系统的运行,内存空间会不断增长,直到整个系统内存被占满而导致内存溢出,最终宕机。
(2)把UnpooledByteBufAllocator换成 PooledByteBufAllocator,再进行试验,看看服务器的内存使用量情况。
实验的参考结果:内存使用量基本能维持在一个连接占用1MB左右 的内存空间,内存使用量保持在10GB左右,经过长时间的运行测试, 我们会发现内存使用量能维持在这个数量附近,系统不会因为内存被耗尽而崩溃。
池化和非池化分配器设置
在 Netty 中,默认的分配器为 ByteBufAllocator.DEFAULT。该默认的分配器可以通过系统参数(System Property)选项 io.netty.allocator.type 进行配置,配置时使用字符串值:”unpooled”,”pooled”。不同的 Netty版本,对于分配器的默认使用策略是不一样的。在 Netty 4.0 版本中,默认的分配器为UnpooledByteBufAllocator(非池化内存分配器)。在Netty 4.1版本中,默认的分配器为 PooledByteBufAllocator(池化内存分配器),初始化代码在 ByteBufUtil 类中的静态代码中,具体如下:
1 | static { |
现在PooledByteBufAllocator已经广泛使用了一段时间,并且有了增强的缓冲区泄漏追踪机制。因此也可以在Netty程序中设置引导类 Bootstrap 装配的时候将 PooledByteBufAllocator 设置为默认的分配器。
1 | ServerBootstrap b = new ServerBootstrap(); |
分配器的多种使用方法
使用缓冲区分配器创建 ByteBuf 的方法有多种,可以根据实际需要进行选择。下面列出几种主要的:
1 |
|
ByteBuf 的类型
类型的介绍
根据内存的管理方不同,缓冲区分为堆缓冲区和直接缓冲区,也就是 Heap ByteBuf和Direct ByteBuf。另外,为了方便缓冲区进行组合, 还提供了一种组合缓存区。
| 类型 | 说明 | 优点 | 不足 |
|---|---|---|---|
| Heap ByteBuf | 内部数据为 Java 数组,存储在 JVM 堆空间中。可通过 hasArray 判断是否是堆缓冲区。 | 未使用池化的情况下,能提供快速的分配和释放。 | 写入底层传输通道之前,都会复制到直接缓冲区。 |
| Direct ByteBuf | 内部数据存储在操作系统的物理内存(堆外)中。 | 能获取超过 JVM 堆限制的内存;写入传输通道比堆缓冲区更快。 | 释放和分配空间昂贵(需调用 OS malloc 方法);在 Java 中读取数据时需复制一次到堆上。 |
| CompositeBuffer | 多个缓冲区的组合表示。 | 方便一次性操作多个缓冲区实例。 |
上面三种缓冲区都可以通过池化(Pooled)、非池化 (Unpooled)两种分配器来创建和分配内存空间。对于 Direct Memory(直接内存):
- Direct Memory 不属于 Java 堆内存,所分配的内存其实是调用操作系统 malloc() 函数来获得的,由 Netty 的本地 Native 堆进行管理。
- Direct Memory 容量可通过
-XX:MaxDirectMemorySize来指定, 如果不指定,则默认与 Java 堆的最大值(-Xmx指定)一样。注意:并不是强制要求,有的 JVM 默认Direct Memory与-Xmx 值无直接关系。 - 在需要频繁创建缓冲区的场合,由于创建和销毁Direct Buffer(直接缓冲区)的代价比较高昂,因此不宜使用Direct Buffer。也就是说,Direct Buffer尽量在池化分配器中分配和 回收。如果能将Direct Buffer进行复用,在读写频繁的情况下 就可以大幅度改善性能。
- 对Direct Buffer的读写比Heap Buffer快,但是它的创建和销 毁比普通Heap Buffer慢。
- 在Java的垃圾回收机制回收Java堆时,Netty框架也会释放不再 使用的Direct Buffer缓冲区,因为它的内存为堆外内存,所以 清理的工作不会为Java虚拟机(JVM)带来压力。注意一下垃圾 回收的应用场景:①垃圾回收仅在Java堆被填满,以至于无法 为新的堆分配请求提供服务时发生;②在Java应用程序中调用 System.gc()函数来释放内存。
两类缓冲区的使用
对于 Heap ByteBuf 和 Direct ByteBuf 两类缓冲区的使用,它们有以下几点不同:
- Heap ByteBuf 通过调用分配器的 buffer() 方法来创建;Direct ByteBuf 通过调用分配器的 directBuffer() 方法来创建。
- Heap ByteBuf 缓冲区可以直接通过 array() 方法读取内部数组; Direct ByteBuf 缓冲区不能读取内部数组。
- 可以调用
hasArray()方法来判断是否为 Heap ByteBuf 类型的缓冲区;如果 hasArray() 返回值为 true,则表示是堆缓冲,否则为直接内存缓冲区。 - 从Direct ByteBuf 读取缓冲数据进行Java程序处理时,相对比较麻烦,需要通过 getBytes/readBytes 等方法先将数据复制到 Java 的堆内存,然后进行其他的计算。
Heap ByteBuf 和 Direct ByteBuf 这两类缓冲区的使用案例:
1 |
|
Unpooled 工具类
为了快速创建 ByteBuffer,Netty 提供了一个非常方便的获取缓冲区的类——Unpooled,用它可以创建和使用非池化的缓冲区。 Unpooled 的使用也很容易,如下是几个使用例子:
1 | // 创建堆缓冲区 |
除了在 Netty 开发中使用之外,Unpooled 类的应用场景还包括不需要其他Netty组件(除了缓冲区之外)甚至无网络操作的场景,从而使 得 Java 程序可以使用 Netty 的高性能、可扩展的缓冲区技术。Unpooled 类可用于在 Netty应用之外的其他程序中独立使用ByteBuf缓冲区。
Context.alloc 方法
在处理器的开发过程中(这个为 Netty 应用开发的主要工作),推荐通过调用 Context.alloc() 方法来获取通道的缓冲区分配器来创建ByteBuf。
1 | public class AllocatorTest { |
1 | ===========入站的ByteBuf============ |
以上代码的 AllocDemoHandler 处理器调用 ctx.alloc().buffer() 方法获取 ByteBuf,有关 ctx.alloc() 方法的源码如下:
1 | abstract class AbstractChannelHandlerContext { |
通过源码可以看出,ctx.alloc()方法所获取的分配器是通道的缓 冲区分配器。该分配器可以通过Bootstrap引导类为通道进行配置,也 可以直接通过channel.config().setAllocator()为通道设置一个缓冲 区分配器。
ByteBuf 的自动创建和释放
ByteBuf 的自动创建
在入站处理时,Netty 是何时自动创建入站的 ByteBuf 缓冲区的呢?查看Netty源代码,我们可以看到,Netty的Reactor线程会通过底 层的Java NIO通道读数据。发生NIO读取的方法为 AbstractNioByteChannel.NioByteUnsafe.read(),其代码如下:
1 | public void read() { |
分配缓冲区的时候,为什么要计算大小呢?从通道里读取数据时 是不知道接收到数据的具体大小的,那么申请的缓冲区究竟要多大 呢?首先,不能太大,太大了浪费;其次,也不能太小,太小了又不够,就需要进行缓冲区的扩容,会影响性能。所以,需要推测要申请 的缓冲区大小。Netty设计了一个RecvByteBufAllocator大小推测接口 和一系列的大小推测实现类,以帮助进行缓冲区大小的计算和推测。 默认的缓冲区大小推测实现类为AdaptiveRecvByteBufAllocator,其特点是能够根据上一次接收数据的大小来自动调整下一次缓冲区创建时分配的空间大小,从而避免内存浪费。
ByteBuf 的自动释放
首先来看一个问题:在入站处理完成时,入站的ByteBuf是如何自动释放的呢?
入站时的自动释放
方式一:TailContext自动释放
Netty 默认会在 ChannelPipline 的最后添加一个 TailContext(尾部上下文,也是一个入站处理器)。它实现了默认的入站处理方法, 在这些方法中会帮助完成ByteBuf内存释放的工作。所以,只要最初的ByteBuf数据包一路向后传递,进入流水线的末 端,TailContext(末尾处理器)就会自动释放掉入站的ByteBuf实例。其源码大致如下:
1 | public class DefaultChannelPipeline implements ChannelPipeline { |
如何让ByteBuf数据包通过流水线一路向后传递,到达末尾的 TailContext 呢?如果自定义的 InboundHandler(入站处理器)继承自 ChannelInboundHandlerAdapter 适配器,那么可以在入站处理方法中调用基类的入站处理方法,演示代码如下:
1 | public class DemoHandler extends ChannelInboundHandlerAdapter { |
当然,如果没有调用父类的入站处理方法将ByteBuf缓存区向后传递,则需要手动进行释放。
方式二:SimpleChannelInboundHandler 自动释放
如果 Handler 业务处理器需要截断流水线的处理流程,不将 ByteBuf 数据包送入流水线末端的 TailContext 入站处理器,并且也不愿意手动释放 ByteBuf 缓冲区实例,那么该怎么办呢?继承 SimpleChannelInboundHandler,利用它的自动释放功能来完成。
以入站读数据为例,Handler业务处理器可以继承自 SimpleChannelInboundHandler 基类,此时必须将业务处理代码移动到 重写的 channelRead0(ctx, msg) 方法中。SimpleChannelInboundHandle 类的入站处理方法(如channelRead 等)会在调用完实际的 channelRead0() 方法后帮忙释放ByteBuf实例。 如果想看看SimpleChannelInboundHandler 是如何释放ByteBuf 的,那 么可以看看Netty源代码。截取的部分代码如下:
1 | /** |
出站时的自动释放
出站缓冲区的自动释放方式是HeadContext自动释放。出站处理用 到的ByteBuf缓冲区一般是要发送的消息,通常是由Handler业务处理 器所申请分配的。例如,通过write()方法写入流水线时,调用 ctx.writeAndFlush(ByteBuf msg),就会让ByteBuf缓冲区进入流水线 的出站处理流程。在每一个出站Handler业务处理器中的处理完成后, 数据包(或消息)会来到出站处理的最后一棒 HeadContext,在完成数据输出到通道之后,ByteBuf 会被释放一次,如果计数器为零,就将被彻底释放掉。
在出站处理的流水处理过程中,在最终进行写入刷新的时候, HeadContext 要通过通道实现类自身实现的doWrite() 方法将 ByteBuf 缓冲区的字节数据发送出去(比如复制到内部的Java NIO通道),发送完成后,doWrite() 方法就会减少 ByteBuf 缓冲区的引用计数,代码大致如下:
1 | public abstract class AbstractNioByteChannel extends AbstractNioChannel { |
总之,在Netty应用开发中,必须密切关注ByteBuf缓冲区的释 放。如果释放不及时,就会造成Netty的内存泄漏, 最终导致内存耗尽。
玩转 ByteBuf 浅层复制
首先说明浅层复制是一种非常重要的操作,可以很大程度地避免内存复制。这一点对于大规模消息通信来说是非常重要的。ByteBuf 的浅层复制分为两种:切片(slice)浅层复制和整体(duplicate)浅层复制。ByteBuf 的 slice() 方法可以获取到一个 ByteBuf 的切片。一个 ByteBuf 可以进行多次切片浅层复制;多次切片后的 ByteBuf 对象可以共享一个存储区域。
slice切片浅层复制
Slice()方法有两个重载版本:
- public ByteBuf slice()
- public ByteBuf slice(int index, int length)
第一个是不带参数的slice()方法,在内部调用了带参数的重载版 本,调用大致方式为:
1 | public abstract class AbstractByteBuf extends ByteBuf { |
也就是说,第一个无参数slice()方法的返回值是 ByteBuf 实例中可读部分的切片。带参数的 slice(int index, int length) 方法可以通过灵活地设置不同起始位置和长度来获取到 ByteBuf 不同区域的切片。一个简单的slice的使用示例代码如下:
1 |
|
1 | ---------------- 动作:分配ByteBuf(9, 100) ---------------- |
调用slice()方法后,返回的切片是一个新的ByteBuf对象。切片后的新ByteBuf有两个特点:
- 切片不可以写入,原因是:maxCapacity与writerIndex值相 同。
- 切片和源ByteBuf的可读字节数相同,原因是:切片后的可读字节数为自己的属性 writerIndex – readerIndex,也就是源 ByteBuf的readableBytes() - 0。
切片后的新ByteBuf和源ByteBuf的关联性如下:
- 切片不会复制源ByteBuf的底层数据,底层数组和源ByteBuf的 底层数组是同一个。
- 切片不会改变源ByteBuf的引用计数。
- 从根本上说,slice() 无参数方法所生成的切片就是源ByteBuf 可读部分的浅层复制。
duplicate 整体浅层复制
和slice切片不同,duplicate()方法返回的是源ByteBuf的整个对象的一个浅层复制,包括如下内容:
- Duplicate() 的读写指针、最大容量值,与源ByteBuf的读写指针相同。
- duplicate() 不会改变源 ByteBuf 的引用计数。
- duplicate() 不会复制源 ByteBuf 的底层数据。
- duplicate()和slice()方法都是浅层复制。不同的是,slice()方 法是切取一段的浅层复制,而duplicate()是整体的浅层复制。
浅层复制的问题及解决
浅层复制方法不会实际去复制数据,也不会改变ByteBuf的引用计 数,会导致一个问题:在源ByteBuf调用release()方法之后,一旦引 用计数为零,就变得不能访问了;在这种场景下,源ByteBuf的所有浅 层复制实例也不能进行读写了;如果强行对浅层复制实例进行读写, 则会报错。
因此,在调用浅层复制实例时,可以通过调用一次 retain() 方法来增加引用,表示它们对应的底层内存多了一次引用,引用计数为2。 在浅层复制实例用完后,需要调用 两次 release()方法来达到彻底释放内存。正确的操作准则是,假设你创建了一个浅拷贝并希望它在异步任务中安全存在,请务必:
- 创建后立即
retain()(计数变为 2,因为初始计数为1)。 - 原对象用完
release()(计数变为 1)。 - 浅拷贝用完
release()(计数变为 0,内存释放)。 - 整个过程中遵循 “谁 retain,谁就要负责对应的 release”。